Coroutine Suspending Functionsを理解したい1
導入
今更ながらCoroutineのsuspendを不思議に感じることが増えてきて、なんとなくステートマシンで動いているらしいとかいう曖昧な理解のまま使っているのも癪なので本腰入れて調べてみることにする。タイトルに1と書いてあるのはちょっとずつでもアウトプットしたほうが良いだろうという理由と単純に文章量が増えそうだと思ったからである。とりあえず納得できるまでシリーズ化する予定。
Coroutineの説明は特にしないけど、以下のようにCoroutine内でsuspend修飾子がついたfunの処理をどう中断しているのかが気になっている点。
fun main(args: Array<String>) { CoroutineScope(Dispatchers.Main).launch { println("start") greet() println("end") } } suspend fun greet() { delay(1000) println("suspended!!") }
Continuation
なにはともあれまずはBytecode変換から。以下のprintlnするだけのsuspend funを変換すると
suspend fun greet() { println("suspended!!") }
こうなる。
public final static greet(Lkotlin/coroutines/Continuation;)Ljava/lang/Object;
@Lorg/jetbrains/annotations/Nullable;() // invisible
// annotable parameter count: 1 (visible)
// annotable parameter count: 1 (invisible)
@Lorg/jetbrains/annotations/NotNull;() // invisible, parameter 0
L0
LINENUMBER 4 L0
LDC "suspended!!"
ASTORE 1
L1
ICONST_0
ISTORE 2
L2
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
ALOAD 1
INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/Object;)V
L3
L4
LINENUMBER 5 L4
GETSTATIC kotlin/Unit.INSTANCE : Lkotlin/Unit;
ARETURN
L5
LOCALVARIABLE $completion Lkotlin/coroutines/Continuation; L0 L5 0
MAXSTACK = 2
MAXLOCALS = 3
Bytecodeに変換するとKotlinのコードでは存在しなかったContinuationというものが引数に渡っている。
KotlinのソースコードではContinuationは以下のように定義されている。
メンバーにCoroutineContextを持ちfunにresumeWithを持つインターフェースになっている。コメントをそのまま訳すと中断後の継続を表すインターフェースがContinuationであり、Continuationに対応するCoroutineのコンテキストをメンバーに持ち、resumeWithで対応するCoroutineの実行を再開する、とのこと。
Coroutineにおける処理の実体がContinuationという気配を感じる。
/** * Interface representing a continuation after a suspension point that returns a value of type `T`. */ @SinceKotlin("1.3") public interface Continuation<in T> { /** * The context of the coroutine that corresponds to this continuation. */ public val context: CoroutineContext /** * Resumes the execution of the corresponding coroutine passing a successful or failed [result] as the * return value of the last suspension point. */ public fun resumeWith(result: Result<T>) }
ここで先程の変換したBytecodeをjavaにDecompileしてみる
public final class TestKt { @Nullable public static final Object greet(@NotNull Continuation $completion) { String var1 = "suspended!!"; boolean var2 = false; System.out.println(var1); return Unit.INSTANCE; } }
kotlinのsuspend関数と比較して引数にContinuationが渡っていること以外は大きな差は見られない
次にsuspend関数をCoroutineScopeでラップしたものをDecompileしてみる
fun main(args: Array<String>) { CoroutineScope(Dispatchers.Main).launch { println("start") greet() println("end") } } suspend fun greet() { println("suspended!!") }
... public static final void main(@NotNull String[] args) { Intrinsics.checkParameterIsNotNull(args, "args"); BuildersKt.launch$default(CoroutineScopeKt.CoroutineScope((CoroutineContext)Dispatchers.getMain()), (CoroutineContext)null, (CoroutineStart)null, (Function2)(new Function2((Continuation)null) { private CoroutineScope p$; Object L$0; int label; @Nullable public final Object invokeSuspend(@NotNull Object $result) { Object var5 = IntrinsicsKt.getCOROUTINE_SUSPENDED(); CoroutineScope $this$launch; String var3; boolean var4; switch(this.label) { case 0: ResultKt.throwOnFailure($result); $this$launch = this.p$; var3 = "start"; var4 = false; System.out.println(var3); this.L$0 = $this$launch; this.label = 1; if (TestKt.greet(this) == var5) { return var5; } break; case 1: $this$launch = (CoroutineScope)this.L$0; ResultKt.throwOnFailure($result); break; default: throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine"); } var3 = "end"; var4 = false; System.out.println(var3); return Unit.INSTANCE; } @NotNull public final Continuation create(@Nullable Object value, @NotNull Continuation completion) { Intrinsics.checkParameterIsNotNull(completion, "completion"); Function2 var3 = new Function2(completion) { private CoroutineScope p$; Object L$0; int label; @Nullable public final Object invokeSuspend(@NotNull Object $result) { Object var5 = IntrinsicsKt.getCOROUTINE_SUSPENDED(); CoroutineScope $this$launch; String var3; boolean var4; switch(this.label) { case 0: ResultKt.throwOnFailure($result); $this$launch = this.p$; var3 = "start"; var4 = false; System.out.println(var3); this.L$0 = $this$launch; this.label = 1; if (TestKt.greet(this) == var5) { return var5; } break; case 1: $this$launch = (CoroutineScope)this.L$0; ResultKt.throwOnFailure($result); break; default: throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine"); } var3 = "end"; var4 = false; System.out.println(var3); return Unit.INSTANCE; } ...
...で省略しているがDecompileした内で public final Continuation create(@Nullable Object value, @NotNull Continuation completion) { が無限にネストしそうな気配だった。(Decompile処理自体がいつまでたっても終了しなかった)
上記のコードを見てsuspend関数がcontinuation passing-styleで実装されているという話とstate machineが少しだけ紐付いてきた気がする。
続きはまた今度。
参考
1) Suspending functions, coroutines and state machines - Pedro Felix Labs
2) https://www.infoq.com/jp/articles/kotlin-coroutines-bottom-up/
3) https://medium.com/google-developer-experts/coroutines-suspending-state-machines-36b189f8aa60
4) https://github.com/Kotlin/KEEP/blob/master/proposals/coroutines.md
ViewPagerからViewPager2に移行するときのちょっとした罠
ちゃんとした記事を書きたいけど投稿しないよりマシなので小ネタ投稿
ViewPagerを0以外のpositionで起動したいときに以下のようにすると思う.
view_pager.currentItem = 1
内部的にはsetCurrentItemInternalのsmoothScrollという値にfalseが渡っていてこれが渡っているとアニメーションなしでViewPagerのpositionが変わる.
public void setCurrentItem(int item) { mPopulatePending = false; setCurrentItemInternal(item, !mFirstLayout, false); } /** * Set the currently selected page. * * @param item Item index to select * @param smoothScroll True to smoothly scroll to the new item, false to transition immediately */ public void setCurrentItem(int item, boolean smoothScroll) { mPopulatePending = false; setCurrentItemInternal(item, smoothScroll, false); }
ViewPager2でも同じようなことができるが実はこう書くとViewPagerと違う挙動になる.
view_pager2.currentItem = 1
内部的にはsmoothScrollにtrueが渡るので謎にanimationがかかったりpositionが移動しなかったりする.
public void setCurrentItem(int item) { setCurrentItem(item, true); } /** * Set the currently selected page. If {@code smoothScroll = true}, will perform a smooth * animation from the current item to the new item. Silently ignored if the adapter is not set * or empty. Clamps item to the bounds of the adapter. * * @param item Item index to select * @param smoothScroll True to smoothly scroll to the new item, false to transition immediately */ public void setCurrentItem(int item, boolean smoothScroll) { if (isFakeDragging()) { throw new IllegalStateException("Cannot change current item when ViewPager2 is fake " + "dragging"); } setCurrentItemInternal(item, smoothScroll); }
ViewPagerのview_pager.currentItem = 1とViewPager2のview_pager.setCurrentItem(1, false)が同等ですという話でした.
以上!
エイシング プログラミング コンテスト 2020 D - Anything Goes to Zero
昨日のD問題,このレベルは本番で出ても難しい. 解答だけ見ると真新しい知識はないんだがビット系の問題はどこから取っ掛かりをつければ良いか勘がつかめていない.
回答時の方針
本番中に提出したのが以下のコード.
Submission #15177835 - AIsing Programming Contest 2020
問題を見てとりあえずビット演算するかという発想になった.まずこれが良くなくて与えられた制約のもとでどの程度の計算量になるか見積もるべきだった.bitsetを初めて使ったわけだがbitsetのcount()の計算量が普通に考えればO(N)なんだけど,本番中は希望的観測でO(1)でいけるのではという発想になってしまってbitsetのcountを使う実装でゴリ押ししてしまった.コード提出した結果やっぱり無理かと思ってビットカウントを高速化する課題だということに気づいたが時既にお寿司でした.
正答
上述の通りでビットカウントを高速にするのが今回のお題.愚直にやるとカウントするのにO(N)かかってしまうのでこれを高速化する必要がある.私的には今回の問題を解くために必要な発想は以下の通り.
i桁目をビット反転してもビットカウントは
+-1にしかならないi桁目をビット反転したものの値は
+=2^(i-1)になる合同式の性質の利用
2回目以降の処理については高速化の必要がない
入力例1で考えてみると
3 011
もとの値は3でビットカウントは2
3桁目を反転することを考えると0->1だからビットカウントは2+1になり,そのときの値は3+2^(3-1) = 7
各桁反転するとき0か1かでビットカウントをプラスするかマイナスするかが決まり,そのときの値は0であればその桁のぶんだけもとの値に+ 2^(i-1)すればよく1のときは逆に- 2^(i-1)すれば良いことがわかる.
Xi % popcount(Xi) を考えるときにXiは最大200000桁でありオーバーフローする可能性があるため各桁2^iについてpopcount(Xi)の剰余を逐一取りつつ計算する.
元の値とそのビットカウントとをorg_v,org_bとすると各桁を反転したときの値は 0 -> ビットカウント-> org_b+1 値-> (org_v+2^(i-1)) % (org_b+1) 1 -> ビットカウント-> org_b-1 値-> (org_v-2^(i-1)) % (org_b-1)
Submission #15197488 - AIsing Programming Contest 2020
※ポップカウントの計算は高速化の余地あり
いじょー.
6月の振り返りと7月の目標
Android
DIについて記事を書いた. KoinとDagger2のパフォーマンスについて その1 - sky’s 雑記
あと7月入ってRemote Configについて記事を書いた. Firebase Remote Configの挙動について - sky’s 雑記
1記事/月が目標でもう達成したんだが,DIの件はもうちょい詰めたいのでもう1記事書く予定.
大学院
レポートラッシュで死にかけている. 7月は4,5本レポートあって前半の山場を現在迎えているので頑張る. 研究も論文読んだり手を動かしたりしたいけど全然進んでない... 8,9月は少し落ち着きそうなので今月が踏ん張りどころである.
あと若干話変わるんだが,オープンイノベーションという授業の課題でWeb2.0とAjaxについて書いてみてWebの標準化や盛衰の歴史は面白いと思った(今更).Android本職だけど仕事でReactとかは若干書いて,とはいえ今まではただツールとして使っている止まりだったわけだが,Web標準とかの話もちょっと興味が出てきた.
競プロ
レート500弱のAC150である. 最近はdiff800前後であれば解法が浮かばないということは無くなってきて早く正確に解くことに重点が移ってきている.
ツール変えれば良くなるとかは全然思ってないんだが,職業で使ってるJavaでちょっと問題解いて様子見ようかなという感じ. 転職しようと思ったときのコーディングテストとかホワイトボードテストでもJavaを1stチョイスにする可能性が一番高いのでまぁ学習効率という意味でも悪くないかなと思っている.
目標は1000パフォを出すこと.
いじょー.
Firebase Remote Configの挙動について
Remote Configは便利なんですが雰囲気で使うと思ったように動かなかったりするのでちゃんとまとめようと思います.
TL;DL
- fetchAndActivateをするとremoteの値がローカルに保存され参照可能となる
- ローカルキャッシュの期限は最短でも12分でそれ以上の頻度では更新できない
- 参照は通信結果ではなく常にローカルキャッシュの値
概要
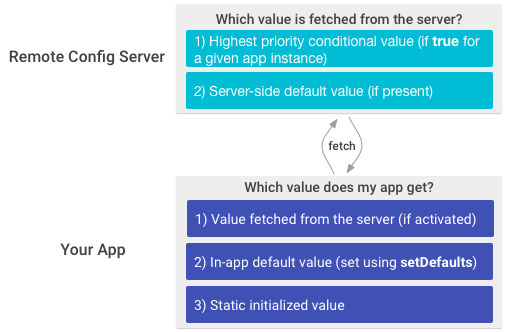
図1. RemoteConfig概要図[1]
抑えておきたい概念は以下の通り
- cache
- fetch/activate
- interval
1個ずつ見ていきます.
cache
Remote Configは常にremoteから値を取得するわけではなく,後述するfetchIntervalにlimitがありそれ以上の頻度ではremoteの値を取得できない仕組みになっています.なので基本的にはローカルのキャッシュを参照してたまにremoteの値を取得すると思ってもらって良いです.Device File Explorerでローカルフォルダを見に行くと以下のようにjsonが保存されていて参照するときはこの値を見ています.(any_key_nameとなってるところがRemote Configで設定したフィールド名で今回はboolを設定していると思ってください)
frc_1/xxxxxxxxxxx/android/xxxxxxxxxxx_firebase_activate.json
{"configs_key":{"any_key_name":"true"},"fetch_time_key":1593480378652,"abt_experiments_key":[]}
ex.kt
remoteConfig.getBoolean("any_key_name")
fetchの設定やログもxmlで保持しています.
frc_1/xxxxxxxxxxx/android/xxxxxxxxxxx_firebase_settings.xml
<?xml version='1.0' encoding='utf-8' standalone='yes' ?> <map> <long name="fetch_timeout_in_seconds" value="5" /> <int name="last_fetch_status" value="-1" /> <boolean name="is_developer_mode_enabled" value="false" /> <long name="minimum_fetch_interval_in_seconds" value="1800" /> <long name="backoff_end_time_in_millis" value="-1" /> <long name="last_fetch_time_in_millis" value="1593480378652" /> <int name="num_failed_fetches" value="0" /> </map>
fetch/activate
cacheの項目でアプリはactivateされたcacheを参照すると記述しましたがfetchを行っただけではjsonファイルは作成されません.fetchをした段階では以下のようなファイルがローカルのdataディレクトリに作成されます,このjsonはremoteの情報を反映したものです.
frc_1/xxxxxxxxxxx/android/xxxxxxxxxxx_firebase_fetch.json
{"configs_key":{"any_key_name":"false"},"fetch_time_key":1593829520560,"abt_experiments_key":[]}
以下のようにactivateすることで初めてfirebase_activate.jsonが作成されます.
return activatedConfigsCache .put(fetchedContainer) .continueWith(executor, this::processActivatePutTask);
return Tasks.call(executorService, () -> storageClient.write(configContainer))
interval
上述のとおりintervalはremoteからフェッチする間隔であり公式によると最短で1時間5回(=12分)のようです.
アプリが短期間に何度もフェッチすると、フェッチ呼び出しが抑制され、SDK から FirebaseRemoteConfigFetchThrottledException が返されます。バージョン 17.0.0 よりも前の SDK では、フェッチ リクエストは 60 分間に 5 回までと制限されていました(新しいバージョンでは制限が緩和されています)。 Android で Firebase Remote Config を使ってみる
デフォルトではインターバルは12時間に設定されます.
public static final long DEFAULT_MINIMUM_FETCH_INTERVAL_IN_SECONDS = HOURS.toSeconds(12);
firebase-android-sdk/ConfigFetchHandler.java at master · firebase/firebase-android-sdk · GitHub
キャッシュの有効期限(=インターバル)が切れていなければローカルの値を読みます.
if (cachedFetchConfigsTask.isSuccessful() && areCachedFetchConfigsValid(minimumFetchIntervalInSeconds, currentTime)) { // Keep the cached fetch values if the cache has not expired yet. return Tasks.forResult(FetchResponse.forLocalStorageUsed(currentTime)); }
firebase-android-sdk/ConfigFetchHandler.java at master · firebase/firebase-android-sdk · GitHub
また,なんらかの理由でremoteのfetchに失敗した場合はエクスポネンシャルバックオフでスロットリングがかかるのでその場合もfetchは行われないようです(exceptionが吐かれる)
Date backoffEndTime = getBackoffEndTimeInMillis(currentTime);
if (backoffEndTime != null) {
// TODO(issues/260): Provide a way for users to check for throttled status so exceptions
// aren't the only way for users to determine if they're throttled.
fetchResponseTask =
Tasks.forException(
new FirebaseRemoteConfigFetchThrottledException(
createThrottledMessage(backoffEndTime.getTime() - currentTime.getTime()),
backoffEndTime.getTime()));
} else {
まとめ
仕組みがわかれば特に難しいことはないんですが雰囲気で使うとremoteの値が取得できないとか思った結果と違うものが取得できたみたいなことになりやすいです.最短でも12分間隔でしかfetchできないというのがミソなのでリアルタイム性が求められるような情報はRemote Configとはあまり相性が良くないと言えるかもしれません.
refs
エラトステネスの篩のまとめ
整数にもう少し馴染みたいという気持ちからまとめてみます, 茶とか緑レベルくらいまで通用しそうなところまでです.
それにしてもdiff800の壁が高すぎる... 今acceptが140だけど200くらいで緑コーダーになりたいが遠そうな感じ.
ナイーブ
エラトステネスの篩の定義からは外れるが実装はほとんど同じなので一応書いておく.
候補i以降の全整数にiで割る作業を繰り返し計算量はO(n^ 2)
vector<ll> sieve(ll n) {
vector<ll> prime(n, true);
prime[0] = false;
prime[1] = false;
for(ll i = 2; i < n; i++) {
if(prime[i]) {
for(ll j = 2*i; j < n; j++) {
if(j%i == 0) prime[j] = false;
}
}
}
return prime;
}
√nまでチェックする
nが約数を持つとき1つは必ず√n以下になるという性質を利用したもので計算量はO(n√n). (nの約数のminを最大にしようとすると√n√nになることを考えると理解しやすい) a <= bとしたときabは既に走査済みなのでb*aについては調べる必要がなくなる
vector<ll> sieve(ll n) {
vector<ll> prime(n, true);
prime[0] = false;
prime[1] = false;
ll n2 = sqrt(n) + 1;
for(ll i = 2; i < n2; i++) {
if(prime[i]) {
for(ll j = 2*i; j < n; j++) {
if(j%i == 0) prime[j] = false;
}
}
}
return prime;
倍数のみを篩にかける
一般的にエラとステエネスの篩と言われるとこれを指す.
結局割り切れるのはiの倍数に限られるので無駄なチェックをはぶく. 計算量はn個の要素についてそれぞれ倍数要素をチェックし, n/2+n/3+n/5...となりこれがO(nloglogn)になるらしい.
vector<ll> sieve(ll n) {
vector<ll> prime(n, true);
prime[0] = false;
prime[1] = false;
for(ll i = 2; i < n; i++) {
if(prime[i]) {
for(ll j = i; j < n; j+=i) { // jにiを足してiの倍数要素のみ走査
if(j%i == 0) prime[j] = false;
}
}
}
return prime;
}
参考
エラトステネスのふるいとその計算量 | 高校数学の美しい物語
KoinとDagger2のパフォーマンスについて その1
唯一Koinが優位に立っていたと思っていたラーニングコストについてもDagger Hiltがリリースされ消え去ろうとしていますが,引き続きKoin利用勢としてDIライブラリの仕組みについて見ていこうと思います.
導入
以下のライブラリでKoinとDagger2の速度について比較されていた件で改めてDagger2の仕組みを調べることにしました.
実行環境
implementation "org.koin:koin-android:2.0.0-alpha-3" implementation 'com.google.dagger:dagger:2.16' kapt 'com.google.dagger:dagger-compiler:2.16'

図1. エミュレータでの実行結果
setupに比べるとinjectのパフォーマンスは大きな差は見られない.これについて今の段階では以下のように考察しているがもう少し詳しく知りたいというのが今回の記事の趣旨です.(※ KoinとDagger2のみの比較になります)
Koin
Koinはランタイムでヒープに確保されたインスタンスの参照が必要
 図2. MemoryProfiler->BeanDefinition
図2. MemoryProfiler->BeanDefinition
setup
setupについては以前の記事でも紹介したとおり生成したmoduleをBeanRegistoryのdifinitionsにsetするのが処理の実体となる.moduleの数が増えればそれだけsetupに必要な時間は長くなるはず. koinのインスタンス管理について - sky’s 雑記
inject
injectはsetupで登録したmoduleを参照する処理でありヒープ領域へのアクセスを行う.
Dagger2
Dagger2はannotation processorによりクラスをgenerateする,dexレベルで依存性が解決される.
 図3. classes.dex->classes-dex2jar.jar->InjectionTest_JavaDaggerTest_MembersInjector.class
図3. classes.dex->classes-dex2jar.jar->InjectionTest_JavaDaggerTest_MembersInjector.class
setup
Dagger2の場合はsetupに必要なのはDaggerComponentのインスタンス生成のみ.依存性はdex生成時点で既に解決されているのでアプリケーション起動時のsetupに時間がかからない.
inject
injectについてはsetupで生成したcomponentが保持するinject対象のインスタンスを参照する.
※ この部分が一番不明瞭で処理レイヤーはKoinと変わらないように見えるが2倍以上速度が違う.この速度の差は実装方法に依っているというのが現在の仮説.
次回以降
ということで一番謎なのがinjectの部分ではあるのですが,せっかくなので次回はDagger2のコードジェネレートの部分を詳しくみたいと思う.以上.